Quantum K-nearest neighbor
Contents
Quantum K-nearest neighbor#
Автор(ы):
Введение#
Если вы занимались машинным обучением, то, скорее всего, знакомы с классическим алгоритмом \(k\) ближайших соседей. Он относительно прост, применяется как в задачах классификации, так и в регрессии. Кстати, классический knn можно вспомнить обратившись к лекции от ODS по классическому машинному обучению.
Давайте немножко вспомним задачу классификации с использованием классического \(kNN\) алгоритма:
У нас есть \(\vec{x} \in \{0, 1 \}^N\) – тестовый образец, а также тренировочные образцы – это набор векторов \(\vec{v_i} \in \{0, 1 \}^N\), в котором каждый вектор уже размечен. И наша задача подобрать правильную метку тестовому образцу.
Тогда мы пройдём следующие шаги:
Вычислим похожесть между тестовым образцом и каждым тренировочным образцом.
Найдем \(k\) ближайших к тестовому образцу соседей.
Подсчитаем количество представителей для каждого класса и приписываем метку самого часто встречающегося класса к тестовому образцу.
Самой трудозатратным шагом является вычисление расстояния от тестового образца к каждому тренировочному. Также и в квантовой версии алгоритма.
Note
На текущий момент разработано несколько разных версий квантового алгоритма поиска ближайших соседей. Есть версия основанная расстоянии Хэмминга [LTG21]:
Расстояние Хэмминга между векторами \(\vec{x}\) и \(\vec{v_i}\):
Но в данной работе мы обратим внимание на версию, которая вычисляет fidelity между двумя векторами состояниями.
Пусть задано Гильбертово пространство \(n\) кубитов, размерности \(N = 2^n\). Вектор \(|\psi\rangle \in H\) – это тестовое состояние, для которого нам нужно определить метку.
Пусть \(\{|\phi\rangle: j \in \{0, ..., M - 1 \}\} \subset H\) - это набор тренировочных состояний, для которых мы знаем их метки. \(M = 2^m, m \in \mathbb{Z}\)
Определим fidelity между тестовым состоянием и \(j\)-тым тренировочным \(|\phi_j\rangle\) как
В свою очередь \(F = [F_0, F_1, ..., F_{M-1}]\) - это таблица fidelity значений между тестовым состоянием и каждым из тренировочных.
Заметим, что задача нахождения \(k\) ближайших соседей сводится к задаче нахождения \(k\) максимумов значений fidelity из таблицы \(F\). Для этого мы должны реализовать оракула
где \(f_{y,A}\) - это булева функция определённая как
Алгоритм#
Далее мы алгоритм представленный в работе [BAG21].
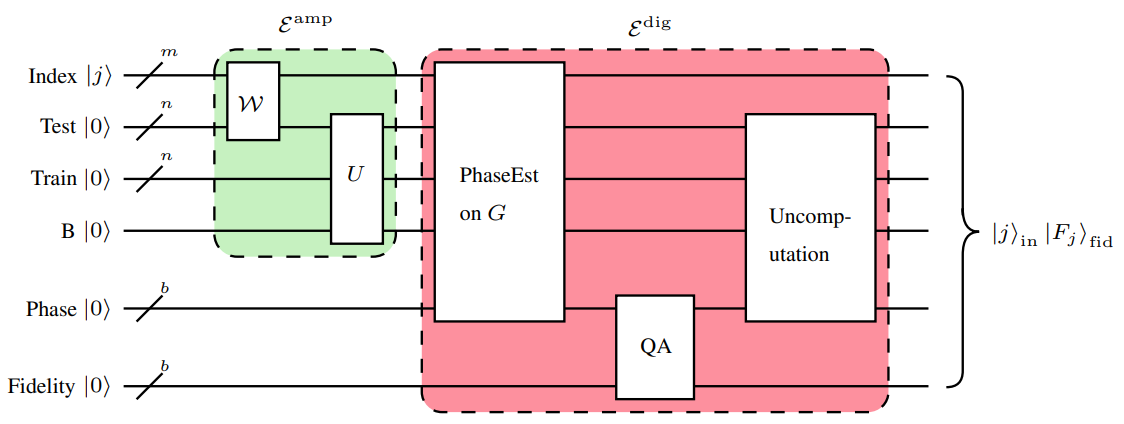
Fig. 67 Принципиальная схема QkNN алгоритма. Взято из работы [BAG21].#
Квантовый алгоритм поиска \(k\) ближайших соседей будет состоять из двух основных шагов:
Используй оракул \(O_{y,A}\) (для алгоритма Гровера) мы находим \(k\) состояний \(\{|\phi_{j1}\rangle, ..., |\phi_{jk}\rangle\}\) для которых значение fidelity с тестовым состоянием максимально.
Найти преобладающую метку среди \(k\) найденных состояний и присвоить её тестовому состоянию.
Самой нетривиальной задачей для нас будет построение оракула \(O_{y,A}\).
Вначале нужно составить оператор \(\mathcal{F}\), который выполняет преобразование вида:
\[ \mathcal{F}|j\rangle|0\rangle = |j\rangle|F_j\rangle \]для \(j \in \{0, ..., M-1\}\). \(|F_j\rangle\) – это одно из базисных состояний вычислительного базиса (выражающее двоичное представление числа \(F_j\)).
Выполняется преобразование: \(\xi^{amp}|j\rangle|0\rangle = |j\rangle|\psi_j\rangle\). В амплитуду состояния \(|\psi_j\rangle\) закодирована информация о числе \(F_j\) Делается это с помощью Swap test.
Swap test это применение контролируемой операции \(Swap\), которым можно пользоваться для того, чтобы статистически определять fidelity: \(F(\psi, \phi) = |\langle \psi | \phi\rangle|^2\) между двумя произвольными чистыми состояниями \(|\psi\rangle\) и \(|\phi\rangle\).
\[\begin{split} CSWAP(|0\rangle|\psi\rangle|\phi\rangle) = |0\rangle|\psi\rangle|\phi\rangle\\ CSWAP(|1\rangle|\psi\rangle|\phi\rangle) = |1\rangle|\psi\rangle|\phi\rangle \end{split}\]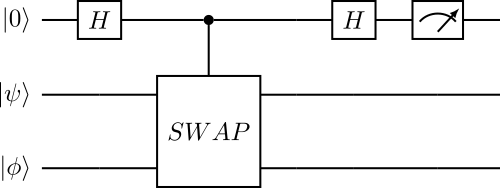
Fig. 68 Схема Swap test#
Выполняется преобразование \(\xi^{dig}|j\rangle|\psi_j\rangle = |j\rangle|F_j\rangle\)
И тогда \(\mathcal{F} = \xi^{dig}\xi^{amp}\).
Берём 2 пары регистров \(i_1, f_1; i_2, f_2\). Инициализируются они в форме \(|j\rangle_{i_1}|0\rangle_{f_1}|y\rangle_{i_2}|0\rangle_{f_2}\)
Применяется \(\mathcal{F}\) на каждой паре:
\[ \mathcal{F}(|j\rangle_{i_1}|0\rangle_{f_1}) \mathcal{F}(|y\rangle_{i_2}|0\rangle_{f_2}) = |j\rangle_{i_1}|F_j\rangle_{f_1}|y\rangle_{i_2}|F_y\rangle_{f_2} \]Теперь информация закодирована в регистры и нам нужно реализовать функцию \(f_{y,A}\). И пусть \(\mathcal{C}\) это оператор, реализующий \(f_{y,A}\).
\[ \mathcal{C}(|j\rangle_{i_1}|F_j\rangle_{f_1}|y\rangle_{i_2}|F_y\rangle_{f_2}) = |j\rangle_{i_1}|0\rangle_{f_1}|f_{y,A}\rangle_{i_2}|0\rangle_{f_2} \]
Теперь займёмся вопросом конструирования оракула \(O_{y,A}\). Просьба держаться за ваши кресла.
Вначале мы подготовим состояния. Но чтобы это сделать нам нужны оракулы \(\mathcal{V}, \mathcal{W}\). Как их имплементировать указано в статье, которая указывалась выше.
для всех \(j \in \{0, ..., M-1\}\).
Инициализируем 4 регистра \(i\), \(tr\), \(tst\), \(B\) с соответствующим количеством кубитов в каждом \(m\), \(n\), \(n\), \(1\), где \(n = \log(N)\), \(m = \log(M)\).
\[ |j\rangle_{i}|0^{\otimes n}\rangle_{tr}|0^{\otimes n}\rangle_{tst}|0\rangle_B \]Применяем \(\mathcal{W}\)
\[ \mathcal{W}(|j\rangle_{i}|0^{\otimes n}\rangle_{tr}|0^{\otimes n}\rangle_{tst}|0\rangle_B) = |j\rangle_{i}|\phi_j\rangle_{tr}|0^{\otimes n}\rangle_{tst}|0\rangle_B \]Применяем \(\mathcal{V}\)
\[ \mathcal{V}(|j\rangle_{i}|\phi_j\rangle_{tr}|0^{\otimes n}\rangle_{tst}|0\rangle_B) = |j\rangle_{i}|\phi_j\rangle_{tr}|\psi_j\rangle_{tst}|0\rangle_B \]Применяем swap test между тренировочным регистром \(tr\) и тестовым регистром \(tst\), а регистр \(B\) будет выступать в качестве контрольного.
\[ \frac{1}{2} \left[ \left(|\phi_j\rangle|\psi\rangle_{tst} + |\psi_j\rangle|\phi\rangle_{tst} \right)|0\rangle_B +\left( |\phi_j\rangle|\psi\rangle_{tst} - |\psi_j\rangle|\phi\rangle_{tst} \right)|1\rangle_B \right] = |j\rangle_{i}|\psi_j\rangle_{tr,tst,B} \]Определим \(U\) как унитарное преобразование, которое объединяет шаги 3-4. Кстати, если мы сейчас произведём измерение регистра \(B\), то будем иметь
\[\begin{split} Pr(B = 0) = \frac{1 + F_j}{2} \\ Pr(B = 1) = \frac{1 - F_j}{2} \end{split}\]На этом шаге информация о \(fidelity\) теперь закодирована в амплитуды. Теперь же мы должны перевести \(fidelity\) из амплитуды в число.
Теперь мы будем конструировать новый гейт G. Вообще говоря, он описан в работе [MKF19], где вы можете подробнее с ним ознакомиться.
\[ G = U_{tr,tst,B}\mathcal{W}_{i,tr}S_{0_{tr,tst,B}}\mathcal{W}_{i,tr}^{\dagger}U_{tr,tst,B}^{\dagger}Z_{B}, \]где \(Z_B\) – это действие гейта \(Z\) на регистре \(B\), \(S_0 = I - 2|0\rangle\langle 0|\).
Текущее состояние \(|\psi\rangle_{tr,tst,B}\) может быть представлено в виде композиции двух состояний
\[ |\psi_j\rangle = \frac{-i}{\sqrt{2}}\left(e^{i\pi\theta_j}|\psi_{j+}\rangle - e^{-i\pi\theta_j}|\psi_{j-}\rangle \right) \]Теперь применяем алгоритм QPE (Quantum Phase Estimation), чтобы перевести значение фазы \(\theta_j\) в числовое представление.
\[ QPE(|\psi_j\rangle) = \frac{-i}{\sqrt{2}}|j\rangle_{i}\left[e^{i\pi\theta_j}|\theta_j\rangle_{ph}|\psi_{j+}\rangle_{tr,tst,B} - e^{-i\pi\theta_j}|1 - \theta_j\rangle_{ph}|\psi_{j-}\rangle_{tr,tst,B}\right] = |j\rangle_{i}|\psi_{j,AE}\rangle_{ph,tr,tst,B} \]Применяем алгоритм квантовой арифметики:
\[ |j\rangle|F_j\rangle_{fid}|\psi_{j,AE}\rangle_{ph,tr,tst,B} \]Обнуляем регистры \(ph,tr,tst,B\) и получаем \(|j\rangle_{i}|F_j\rangle_{fid}\) На самом деле шаги 5-9 составляют оператор \(\xi^{dig}\), который мы упоминали ранее.
Теперь применяем оператор \(\mathcal{F}\)
\[ |j\rangle_{i1}|F_j\rangle_{f1}|y\rangle_{i2}|F_y\rangle_{f2} \]Добавим кубит \(Q_1\) для выполнения сравнения
\[\begin{split} J|a\rangle|b\rangle|0\rangle = \begin{cases} |a\rangle|b\rangle|1\rangle : a > b, \\ |a\rangle|b\rangle|0\rangle : a \leq b, \end{cases} \end{split}\]\[ |j\rangle_{i1}|F_j\rangle_{f1}|y\rangle_{i2}|F_y\rangle_{f2}|g(j)\rangle_{Q_1}, \]где
\[\begin{split} g(j) = \begin{cases} 1 : F_j > F_y, \\ 0 : F_j \leq F_y, \end{cases} \end{split}\]По кубиту \(Q_1\) мы сможем распознать все индексы \(j\) для которых \(F_j > F_y\).
Обнуляем регистры \(i2\), \(f2\).
Добавляем ещё один кубит \(Q_2\) для каждого \(i_l \in A\), применяя гейт \(D^{(i_l)}\)
\[\begin{split} D^{(i_l)}|j\rangle|0\rangle = \begin{cases} |j\rangle|1\rangle : j = i_l, \\ |j\rangle|0\rangle : j \neq i_l, \end{cases} \end{split}\]на индексах регистра. И в результате получим состояние
\[ |j\rangle_{i1}|F_j\rangle_{f1}|g(j)\rangle_{Q_1}|\chi_A(j)\rangle_{Q_2} \]О да… Теперь мы добавляем ещё один кубит \(Q_3\). Применяем гейт \(X\) на кубите \(Q_2\) и гейт Тоффоли с контролирующими \((Q_1, Q_2)\) и целевой \(Q_3\)
\[ |j\rangle_{i1}|F_j\rangle_{f1}|g(j)\rangle_{Q_1}|\chi_A(j)\rangle_{Q_2}|f_{y,A}(j)\rangle_{Q_3} \]Обнуляем все регистры, кроме \(Q_3\)
\[ |j\rangle_{i1}|f_{y,A}(j)\rangle_{Q_3} \]Что ж, вот мы и построили преобразование \(O_{y,A}\) которое так хотели
\[ O_{y,A}|j\rangle|0\rangle = |j\rangle|f_{y,A}(j)\rangle \]